Event-Driven Efficient Simulation of Hybrid Dynamical Systems
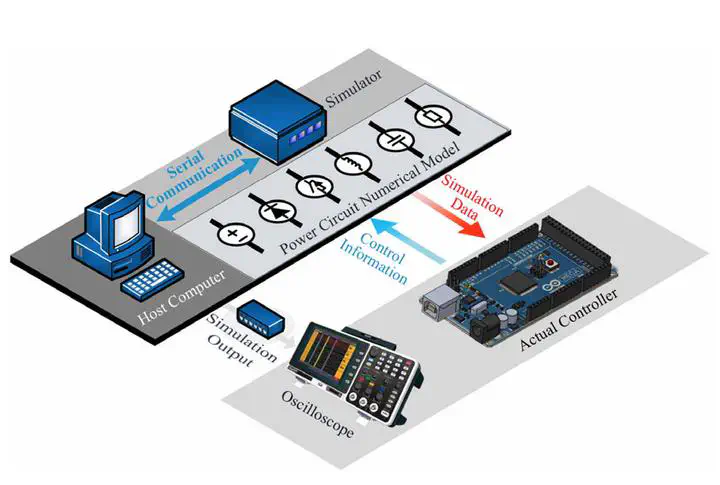
Overview
This project builds a unified event-driven framework for simulating hybrid dynamical systems in power electronics—systems whose dynamics combine continuous ODEs with discrete switching events. Instead of marching with ultra-small, fixed time steps to “catch” switching edges, we predict or schedule switching events first and integrate from event to event, using flexible step sizes and orders. As a result, we achieve offline-grade accuracy and real-time deadlines for high-frequency, large-switch-count converters without relying on exotic hardware.
Just Ask for questions!
Explore our research with an AI assistant powered by the latest Gemini models and reliable sources to enhance your understanding and analysis.
Why This Research
- Fixed-step RT simulators hit a wall. Nanosecond-level steps are needed to capture duty-cycle changes and natural commutation; compute scales badly with system size and switching frequency, pushing costs to high-end FPGAs.
- Sampling delay corrupts inputs. Unsynchronized simulator/controller clocks cause one-step detection delays of PWM edges, misestimating duty cycles and introducing output errors at high frequencies.
- Partitioning can distort physics. Common parallelization inserts artificial delays or L/C elements that alter true dynamics, forcing even smaller steps to compensate.
- Nonlinearity is a blocker. Many specialized fast methods assume PWL behavior; smooth nonlinear components (motors, PV arrays) break these assumptions.
- Goal. A general, hardware-friendly simulation stack that (i) aligns sampling with control, (ii) integrates only when and where physics changes, (iii) parallelizes without distortion, and (iv) handles nonlinear components—all under real-time constraints.
New Measures
- SCED + DHT (TIE 2023). A Synchronous-Cycle Event Detection sampler synchronizes with the controller to precalculate all switching times per cycle, eliminating the usual sampling delay. A Discrete Hybrid Time-step algorithm mixes fixed (per control cycle) and event-driven variable steps with ideal switch models, cutting steps while preserving accuracy.
- PACP without distortion (TPEL 2022). A Parallel Acceleration & Circuit Partitioning solver decouples subcircuits at energy-storage elements and uses high-order derivative continuity to avoid the numerical distortion typical of latency-insertion methods—supporting process-level parallelism on CPUs.
- EDSED-CHIL with VTR (JESTPE 2023). Extends discrete-state event-driven ideas to Controller-HIL via a Virtual-Time-Ratio regulator that triggers simulation/control as events, ensuring precise data-interaction logic and hybrid fixed/variable steps across time scales.
- DAT with SEO (TTE 2024). A Dynamic Adjustable Time-stepping scheme guided by Switch-Event Oversampling: oversample/controller-emulate to predict all switching events of the next cycle, then pre-schedule step sizes and integration orders, including iterative localization of natural commutation. Implemented efficiently on MPSoC.
- Numerical-Derivative Flexible Integrator (TIE 2024). A recursive numerical high-order derivative scheme + PWL/Nonlinear decoupling delivers Taylor-style variable-order integration without needing symbolic derivatives, enabling piecewise-nonlinear systems (switches + smooth nonlinear components).
Impact
- Accuracy at a fraction of cost. Matches offline accuracy while using 1/36 of computation time and 1/20 of hardware cost (PET, 24 switches, 20 kHz); CPU-based real-time feasible.
- Scale and speed. ~3× the simulation scale of a commercial FPGA RT simulator at 1/16 the hardware cost via distortion-free partitioning & parallelism.
- HSF readiness. In a 32-switch modular multi-active bridge at 400 kHz, DAT+SEO improves accuracy by 42× and reduces memory by 90% vs. a commercial HIL, while precisely handling natural commutation.
- Robust CHIL co-timing. VTR-regulated EDSED ensures correct simulator–controller event logic with hybrid step sizes, reducing calculation points and easing PC-class deployment.
- Generalizability. Works under variable and multi-frequency modulation; accommodates smooth nonlinear components; maps to CPUs or MPSoCs with predictable timing.
Publications
Jialin Zheng
Postdoctoral Fellow of Electrical Engineering
My research interests include machine learning, edge computing, and circuit design.